There are many fields under the umbrella of the data science and sometimes these roles look similar to each other or are used interchangeably. Let us list these terms first and try to understand them Different parts within data science can be as following
Big Data
Data Mining
Data Analytics
Data Analysis
Data Science
Machine Learning
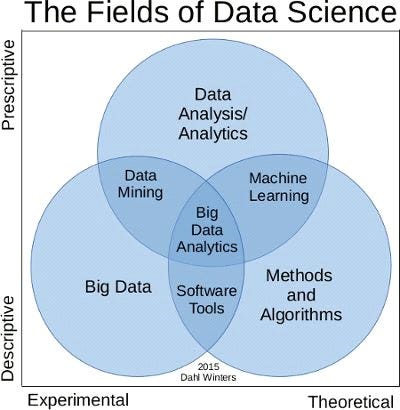
Data science is the umbrella under which all these terminologies take the shelter. Data science is a like a complete subject which has different stages within itself. Suppose a retailer wants to forecast the sales of an X item present in its inventory in the coming month. This is known as a business problem and data science aims to provide optimised solutions for the same. Data science enables us to solve this business problem with a series of well-defined steps. Step 1: Collecting data Step 2: Pre-processing data Step 3: Analysing data Step 4: Driving insights and generating BI reports Step 5: Taking decision based on insights Generally, these are the steps we mostly follow to solve a business problem. All the terminologies related to data science falls under different steps which we are going to understand just in a while. Different terminologies fall under different steps listed above.
Collecting data: To solve any problem using a data-driven approach, the very first thing required at hand is data. In order to analyse anything, we need to have data first. Sometimes data will be given to you in a ready to consume format(which is rare) else you have to gather data from the client database and other sources. Our first terminology, BIG DATA, fits here. Big data is nothing but any data which is too big/complex to handle. Big data does not necessarily mean data which is large in science. Big data is characterised by 3 different properties and if your data exhibits this property then it is qualified to be called Big data. These properties are defined by 3 V’s.
– Volume: Data in terabytes
– Velocity: Streaming data with high throughput
– Veracity: Data with varying structure
In a retail business, a lot of transactions happen every second by a large number of customers, a lot of data is maintained in a structured or unstructured format about customers, employees, stores, sales etc. All this data put together is very complex to process or even comprehend. Big data technologies like Hadoop, Spark, Kafka simplifies our work here.
Cleaning data: This is one task which you will always end up doing. Cleaning data essentially means removing discrepancies from your data such as missing fields, improper values, setting the right format of the data, structuring data from raw files etc. Any process from this point until generating insights falls under the data analysis. It involves extracting, cleaning, transforming, modelling and visualisation of data with an intention to uncover meaningful and useful information that can help in deriving the conclusion and take decisions. Data on which it is applied can be structured or unstructured. We may get data about some retail store which has missing info about an employee’s second name or phone numbers. Knowing how to handle these situations is a part of the data cleaning process
Analysing data: Now we create a plan to do analytics on the data. There can be different types of data analytics which can be performed on the data depending upon the problem at hand. Different types of analytics may include descriptive analytics, predictive analytics, and prescriptive analytics. So we first determine which type of analytics we intend to perform. This is part of data analytics. After getting a structured data from the cleaning operations (which is generally the case), we perform the data mining operation in order to identify and discovering hidden patterns and information in a large dataset. This is known as data mining. For example, identifying seasonality in sales. Data analysis is the more of a holistic approach but data mining tends to find the hidden patterns in data only. These discovered patterns are fed to data analysis approach taken to generate hypothesis and find insights.
Driving insights and BI reports: Once we have analysed data, we gather insight from data which will enable us to take actions. These insights can be based on insights we have gathered through data mining processes or through some predictions. These predictions can come from a mathematical model which will just take into the input parameters and predict some final values.Machine learning is mostly applied at this stage, where we make future predictions and validate our previously defined hypothesis. Machine learning is a technique where we obtain a mathematical model by learning from the patterns present in the data.
Taking actions: Based upon all the insights we have gathered through observation of data or through machine learning model’s result, we get into a state where we can take some decisions regarding any business problem at hand. For example how much stock of item X we need to have in inventory. How much discount should be given to an item X to boost its sales and maintain the trade-off between discount and profit
Different roles in the data science industryThere are multiple roles a professional can take in the data science industry which are in a lot of demand too. These roles all deal with data in some way or the other but are different from each other depending on what you do with data. The Data ScientistHe/she masters a whole range of skills and talents going from being able to handle the raw data, analysing that data with the help of statistical techniques, to share his/her insights with his peers in a compelling way. No wonder these profiles are highly wanted by companies like Google and Microsoft. The Data AnalystHe/She is a master of languages like R, Python, SQL and C. Main responsibility is collecting, processing and performing statistical data analysis. The Data EngineerThe data engineer often has a background in software engineering and loves to play around with databases and large-scale processing systems. The Data ArchitectWith the rise of big data, the importance of the data architect’s job is rapidly increasing. The person in this role creates the blueprints for data management systems to integrate, centralise, protect and maintain the data sources. The data architect masters technologies like Hive, Pig and Spark, and needs to be on top of every new innovation in the industry. The Data StatisticianThe historical leader of data and its insights. Although often forgotten or replaced by fancier sounding job titles, the statistician represents what the data science field stands for: getting useful insights from data The Machine Learning EngineerArtificial intelligence is the goal of a machine learning engineer. They are computer programmers, but their focus goes beyond specifically programming machines to perform specific tasks. They create programs that will enable machines to take actions without being specifically directed to perform those tasks. An example of a system a machine learning engineer would work on is a self-driving car. They take the key role of providing the intelligence to the work done by analysts, for example, forecasting sales of products, segmenting different types of customers based on their habits and traits etc The Business AnalystLess technically oriented, the business analyst makes up for it with his/her deep knowledge of the different business processes. (S)he masters the skill of linking data insights to actionable business insights and is able to use storytelling techniques to spread the message across the entire organization. ConclusionBig Data: Collecting and processing any data which is huge in volume, arrival/processing rate or invariant in structure. Data Mining: Process of finding out hidden patterns in the structured data and find hidden information in the data Data Analytics: It is a process which is one step above data mining. Data analytics identifies the type of the analysis to be performed within which data mining techniques will be performed. Data Analysis: It is a more general approach of finding insights out of the raw data by forming a hypothesis and proving them using statistical tests. Data Science: It defines the process of understanding the business problem to deliver the solution Machine Learning: It is a tool used in data analytics to predict/find out a hidden layer of information in data. An example can be predicting the attrition rate of an organisation/whether an employee will stay in the organisation or leave it. x

















{kind=link}
0 Comments